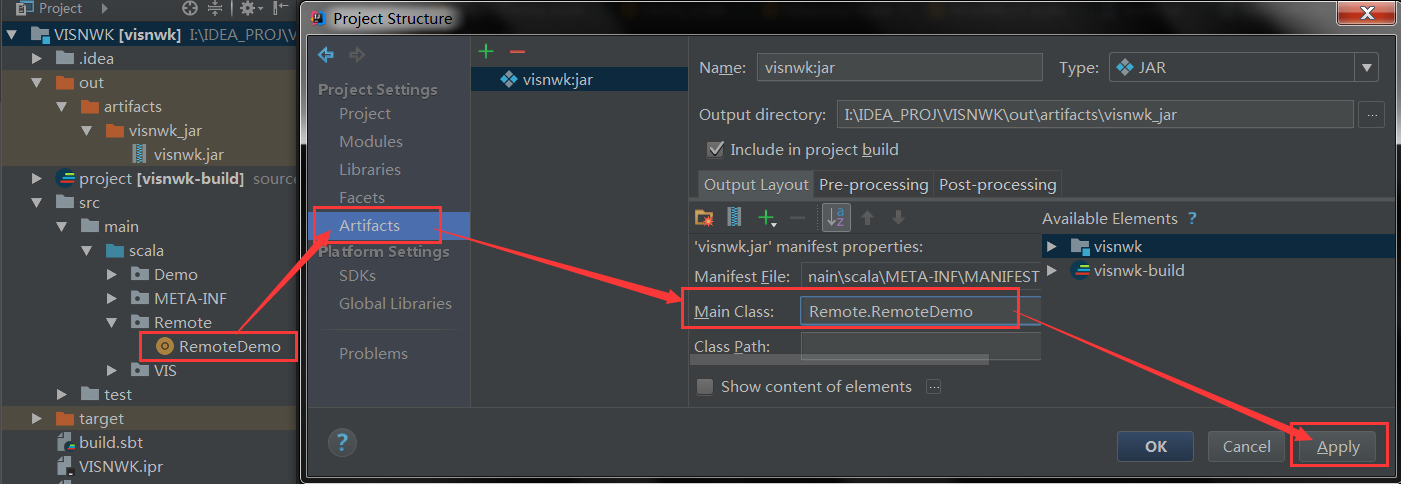
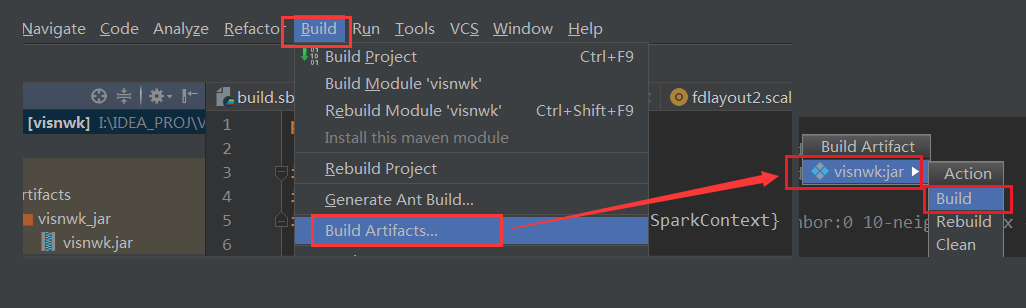
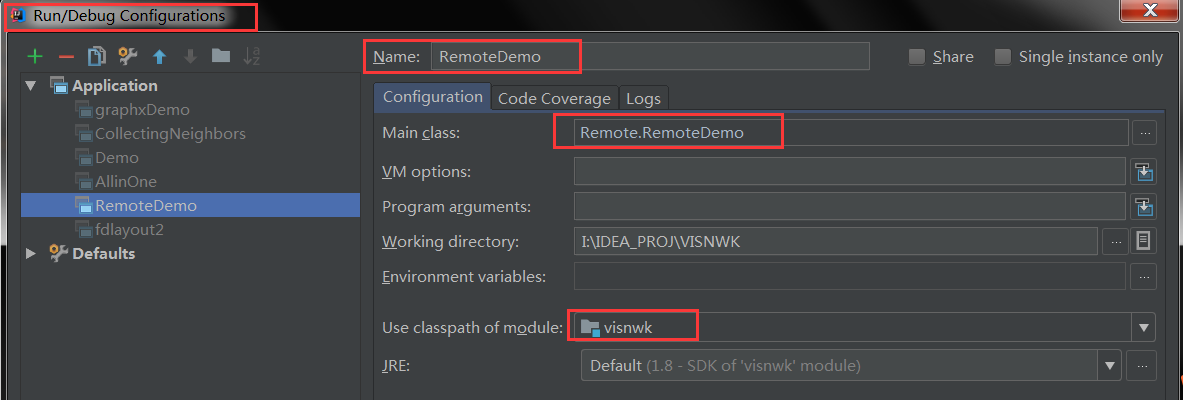
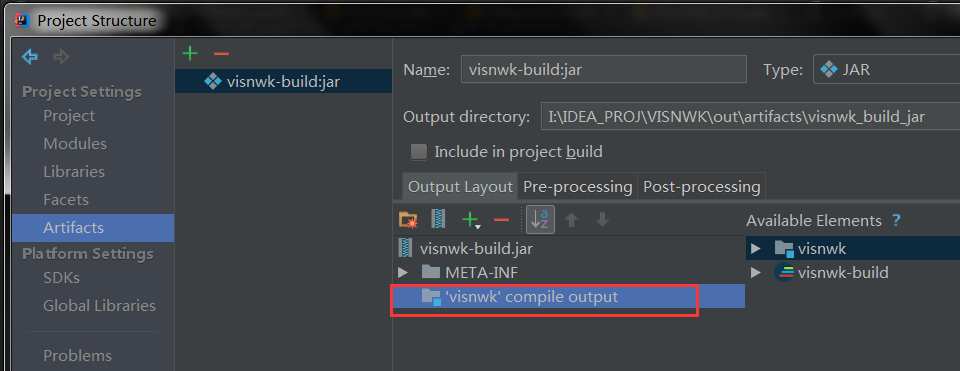
val conf = new SparkConf() .setAppName("SimpleDemo") .setMaster("spark://hadoop01:7077") .setJars(List("I:\\IDEA_PROJ\\VISNWK\\out\\artifacts\\visnwk_jar\\visnwk.jar"))
val sc = new SparkContext(conf)
def loadEdges(fn: String): Graph[Any, String] = { val edges: RDD[Edge[String]] = sc.textFile(fn).filter(l => !(l.startsWith("#"))).map { //无放回 line => val fields = line.split("\t") Edge(fields(0).toLong, fields(1).toLong, "1.0") } val graph: Graph[Any, String] = Graph.fromEdges(edges, "defaultProperty") graph }
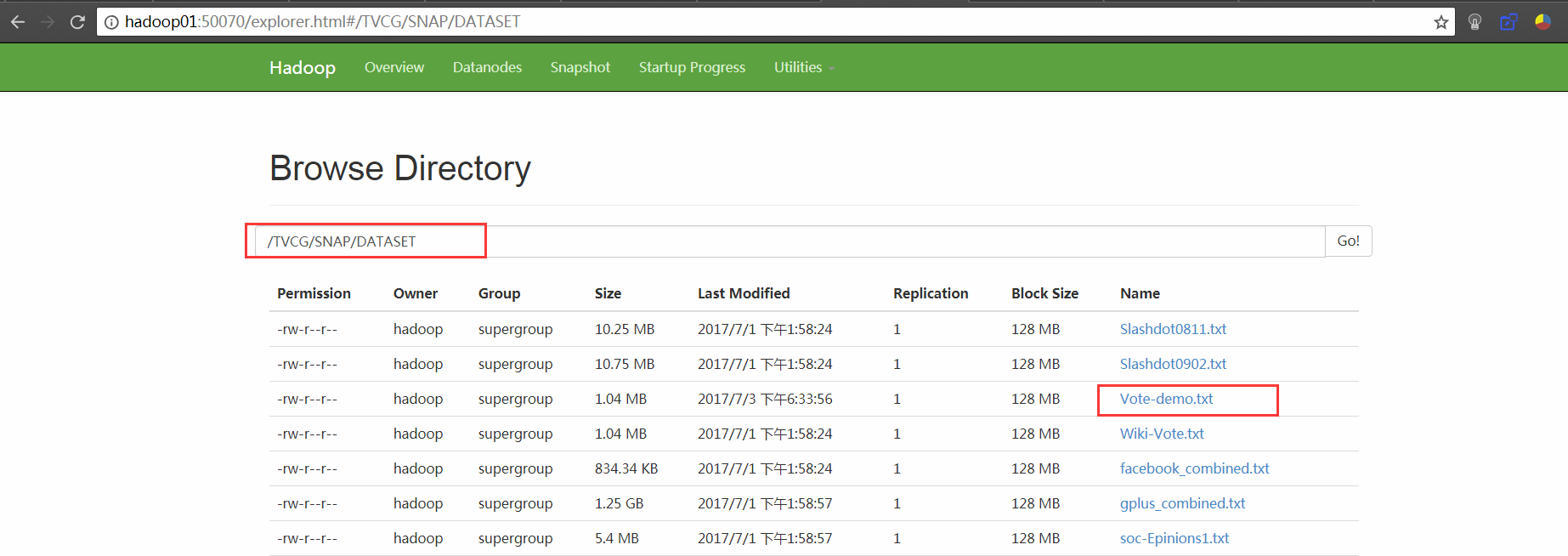
val graph = loadEdges("hdfs://hadoop01:9000/TVCG/SNAP/DATASET/Vote-demo.txt")
[hadoop@hadoop01 bin]$ ./spark-submit --class "Remote.RemoteDemo" ~/visnwk-build.jar 17/07/0319:48:53 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 17/07/03 19:49:03 ERROR TransportRequestHandler: Error while invoking RpcHandler#receive() for one-way message. org.apache.spark.SparkException: Could not find AppClient. at org.apache.spark.rpc.netty.Dispatcher.postMessage(Dispatcher.scala:154) at org.apache.spark.rpc.netty.Dispatcher.postOneWayMessage(Dispatcher.scala:134) at org.apache.spark.rpc.netty.NettyRpcHandler.receive(NettyRpcEnv.scala:644) at org.apache.spark.network.server.TransportRequestHandler.processOneWayMessage(TransportRequestHandler.java:178) at org.apache.spark.network.server.TransportRequestHandler.handle(TransportRequestHandler.java:107) at org.apache.spark.network.server.TransportChannelHandler.channelRead(TransportChannelHandler.java:118) at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:357) at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:343) at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:336) at io.netty.handler.timeout.IdleStateHandler.channelRead(IdleStateHandler.java:287)
//直接用xxxx这个错误IP报错如下 18/05/25 19:06:20 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://118.202.40.210:4042 18/05/25 19:06:20 INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark://xxxxx:7077... 18/05/25 19:06:23 WARN TransportClientFactory: DNS resolution for xxxxx:7077 took 2551 ms 18/05/25 19:06:23 WARN StandaloneAppClient$ClientEndpoint: Failed to connect to master xxxxx:7077 org.apache.spark.SparkException: Exception thrown in awaitResult at org.apache.spark.rpc.RpcTimeout$$anonfun$1.applyOrElse(RpcTimeout.scala:77)
1 2 3 4 5 6 7 8 9
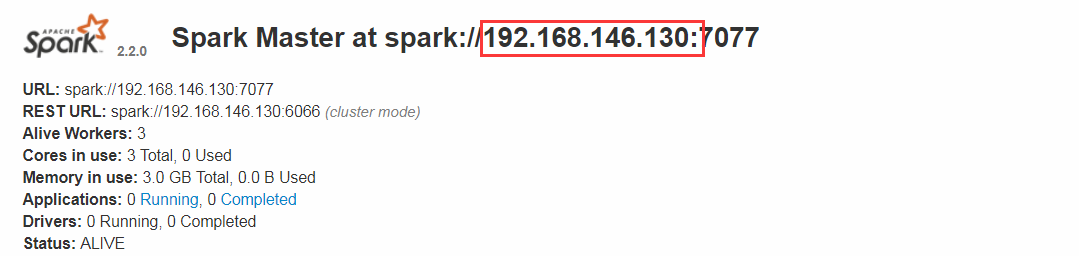
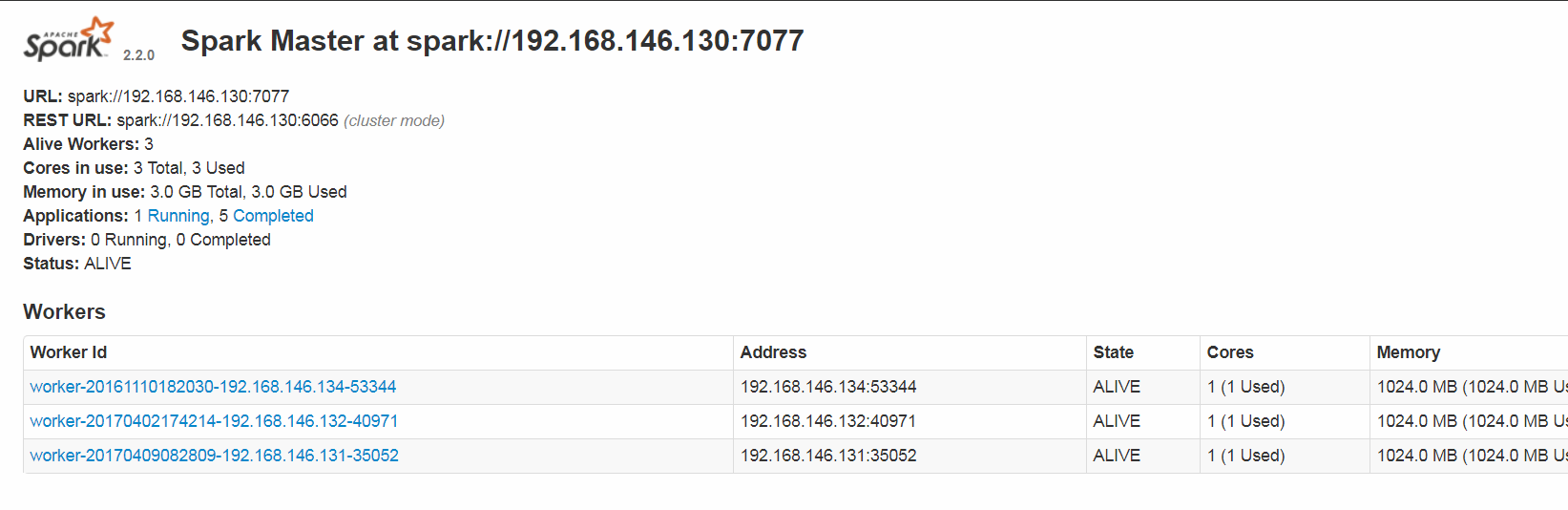
//用master_ip报错如下 18/05/25 19:07:26 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://118.202.40.210:4040 18/05/25 19:07:27 INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark://192.168.146.130:7077... 18/05/25 19:07:27 INFO TransportClientFactory: Successfully created connection to /192.168.146.130:7077 after 23 ms (0 ms spent in bootstraps) 18/05/25 19:07:27 WARN StandaloneAppClient$ClientEndpoint: Failed to connect to master 192.168.146.130:7077 org.apache.spark.SparkException: Exception thrown in awaitResult at org.apache.spark.rpc.RpcTimeout$$anonfun$1.applyOrElse(RpcTimeout.scala:77) //比较上述代码,会发现虽然最后的错误一样,但是中间日志并不一样,所以并不是简单的连接失败
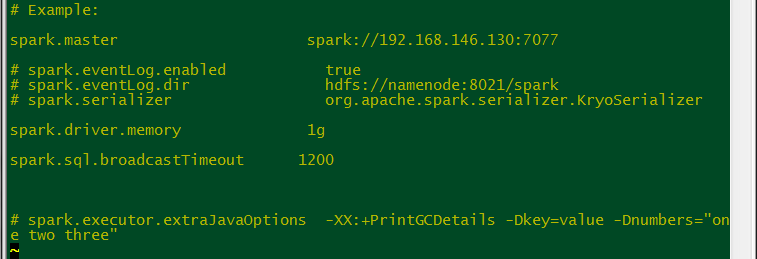
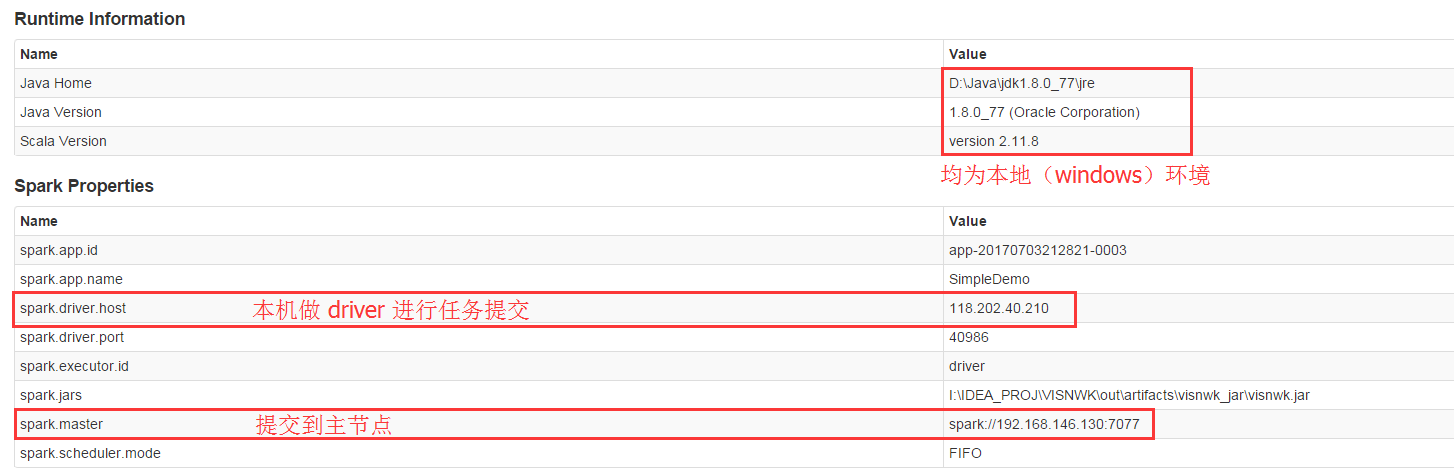
val conf = new SparkConf() .setAppName("SimpleDemo") .setMaster("spark://192.168.146.130:7077") //.setIfMissing("spark.driver.host", "127.0.0.1") // 不设置会默认使用本机的物理IP .setJars(List("I:\\IDEA_PROJ\\VISNWK\\out\\artifacts\\visnwk_jar\\visnwk.jar"))
val sc = new SparkContext(conf)
完美的收官:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
18/05/25 19:25:36 INFO DAGScheduler: Job 0 finished: reduce at EdgeRDDImpl.scala:90, took 60.614562 s graph.edges.count() = 103689 // 终于等到你!! 18/05/25 19:25:36 INFO SparkUI: Stopped Spark web UI at http://118.202.40.210:4040 18/05/25 19:25:36 INFO StandaloneSchedulerBackend: Shutting down all executors 18/05/25 19:25:36 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down 18/05/25 19:25:36 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 18/05/25 19:25:36 INFO MemoryStore: MemoryStore cleared 18/05/25 19:25:36 INFO BlockManager: BlockManager stopped 18/05/25 19:25:36 INFO BlockManagerMaster: BlockManagerMaster stopped 18/05/25 19:25:36 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 18/05/25 19:25:36 INFO SparkContext: Successfully stopped SparkContext 18/05/25 19:25:36 INFO ShutdownHookManager: Shutdown hook called 18/05/25 19:25:36 INFO ShutdownHookManager: Deleting directory C:\Users\msi\AppData\Local\Temp\spark-fae200dd-12cc-4b8a-b2ec-751d641d3689